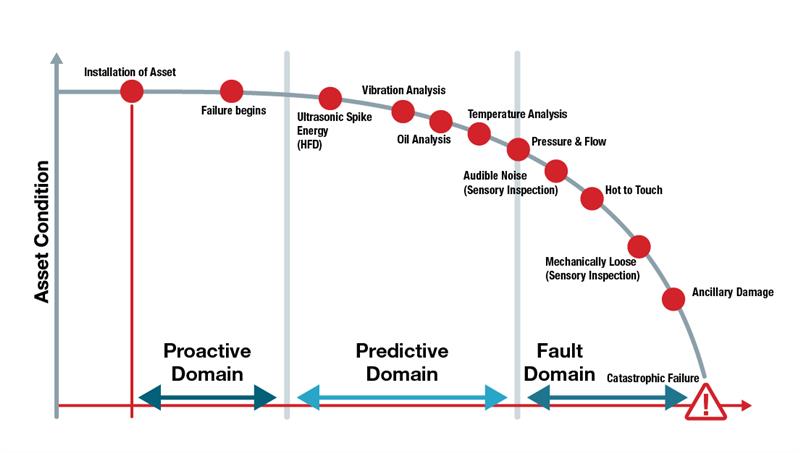
As manufacturers continually look for ways to maximize productivity and eliminate waste, automation sensors are taking on a new role in the plant. Once, sensors were used only to provide detection or measurement data so the PLC could process it and run the machine. Today, sensors with IO-Link measure environmental conditions like temperature, humidity, ambient pressure, vibration, inclination, operating hours, and signal strength. By setting alarm thresholds, it’s possible to program the PLC to use the resulting condition monitoring data to keep machines running smoothly.

Real-time data for real-time response
A sensor with condition monitoring features allows a PLC to use real-time data with the same speed it uses a sensor’s primary process data. This typically requires setting an alarm threshold at the sensor and a response to those alarms at the PLC.
When a vibration threshold is set up on the sensor and vibration occurs, for example, the PLC can alert the machine operator to quickly check the area, or even stop the machine, to look for a product jam, incorrect part, or whatever may be causing the vibration. By reacting to the alarm immediately, workers can reduce product waste and scrap.
Inclination feedback can provide diagnostics in troubleshooting. Suppose a sensor gets bumped and no longer detects its target, for example. The inclination alarm set in the sensor will indicate after a certain degree of movement that the sensor will no longer detect the part. The inclination readout can also help realign the sensor to the correct position.
Detection of other environmental factors, including humidity and higher-than-normal internal temperatures, can also be set, providing feedback on issues such as the unwanted presence of water or the machine running hotter than normal. Knowing these things in real-time can stop the PLC from running, preventing the breakdown of other critical machine components, such as motors and gearboxes.
These alarm bits can come from the sensors individually or combined together inside the sensor. Simple logic, like OR and AND statements, can be set on the sensor in the case of vibration OR inclination OR temperature alarm OR humidity, output a discrete signal to pin 2 of the sensors. Then pin 2 can be fed back through the same sensor cable as a discrete alarm signal to the PLC. A single bit showing when an alarm occurs can alert the operator to look into the alarm condition before running the machine. Otherwise, a simple ladder rung can be added in the PLC to look at a single discrete alarm bit and put the machine into a safe mode if conditions require it.
In a way, the sensor monitors itself for environmental conditions and alerts the PLC when necessary. The PLC does not need to create extra logic to monitor the different variables.

Other critical data points, such as operating hours, boot cycle counters, and current and voltage consumption, can help establish a preventative and predictive maintenance schedule. These data sets are available internally on the sensors and can be read out to help develop maintenance schedules and cut down on surprise downtimes.
Beyond the immediate benefits of the data, it can be analyzed and trended over time to see the best use cases of each. Just as a PLC shouldn’t be monitoring each alarm condition individually, this data must not be gathered in the PLC, as there is typically only a limited amount of memory, and the job of the PLC is to control the machines.
This is where the IT world of high-level supervision of machines and processes comes into play. Part two of my blog will explore how to integrate this sensor data into the IT level for use alongside the PLC.